Bu sabah haberleri okurken yine “yapay zeka hayatımızın her yerinde, yapay zeka dünyayı ele geçirecek” minvalinde bir yazı gördüm. Böyle haberler sizce de artık kabak tadı vermiyor mu? Anlatılan yapay zeka ile bugünkü teknolojiler arasında dağlar kadar fark var ancak YZ etrafındaki temelsiz korkular ve pazarlama çalışmaları bu gerçeği gölgeliyor. Bunun en çarpıcı örneklerinden biri de otonom sürüş, bu sektörün çok güzel bir özeti için batan Starsky Robotics’in kurucusu Stefan Seltz-Axmacher’in bu yazısını inceleyebilirsiniz.
Gelin üstüne çok yazılıp çizilen GPT2–3’ün arkasındaki teknolojiyi, Transformer’ı, derinlemesine inceleyelim. GPT bu teknoloji ile dünyayı yok edebilecek mi, siz karar verin.
Bu yazı herhangi bir yerden çeviri değil, aksine internette Transformer teorisini inceleyen en kapsamlı yazılardan olduğunu düşünüyorum. Bunun nedeni Transformer’ı herkesten daha iyi anlamam değil, tam aksine Transformer’ı tam anlamadığım için en ince detayına kadar araştırmam.
Şimdi okuyacağınız teorinin pratiğe dökülmüş hali için ise Harvard NLP’nin bu kodunu incelemenizi tavsiye ederim.
Teknik terimleri orijinal İngilizce halleri ile yazacağım, bunun sebebi plaza Türkçe’si sevdalısı olmam değil, terimleri daha çok araştırmak isterseniz internette kolayca bulabilmeniz.
Kısaca Transformer
Transformer bir transduction modelidir. Peki transduction nedir? Transdüksiyondur. Biraz daha açıklamam gerekirse transduction, NLP (doğal dil işleme) bağlamında, bir sekansı girdi olarak alıp, başka bir sekansı çıktı olarak veren modellere denir. Örneğin yanlış bir yazımı alıp doğrusunu çıktı olarak verebilir (autocorrect), uzun bir metin alıp kısa bir özet verebilir (özetleme) veya Türkçe bir cümleyi alıp İngilizce’sini verebilir (çeviri). Bu durumlarda bir sekansın diğer sekansa dönüşmesi yani transformasyon söz konusudur, Transformer’ın ismi de buradan gelmektedir.
Transformer’ın ana fikri diğer transduction modellerinin kalbi olan, ve bu yazının devamını anlamak için bilmek gerekmeyen, recurrence (RNN, LSTM, GRU) veya convolution’ı (CNN) atıp bunu tamamen attention, yani dikkat, mekanizması ile değiştirmektir. Attention’ı ilk kez Transformer kullanmıyor ancak Transformer recurrence/convolution kullanmayan ilk nöral transduction modeli.
Transformer teknolojisi bugün BERT şeklinde Google arama ve çeviride kullanılıyor. Buradan modelin arama sonuçlarını ne kadar iyileştirdiğini görebilirsiniz. Transformer’ı, Google Brain araştırmacılarının icat ettiğini de not düşelim.
Transformer’dan önce bu işi LSTM ve RNN’ler yapıyordu. Peki Transformer’ı LSTM ve RNN’lerden daha üstün kılan nedir? Transformer’ın mucitlerine göre üç ana etmen var. Transformer:
· daha hızlı,
· paralel olarak çalıştırmaya daha uygun ve
· daha uzun bağlamlardaki anlamı hatırlayabiliyor.
Bunların ilki çok açık: aynı görevi diğer mimarilere göre daha az işlemle yapıyor. İkincisi de bununla aynı kapıya çıkan bir avantaj: örneğin LSTM kullanırken ederken mimarinin yapısı gereği bir işlemi yapmadan önce başka bir işlemi yapmanız gerekir (2. adımı hesaplamak için 1. adımın hidden state’ına ihtiyaç duyarsınız). Transformer’da ise işlemlerin çoğunu paralel olarak yapabilirsiniz. Sonuncusu ise kitaplar gibi uzun metinlerle çalışmak için çok önemli. Hatta uzun metinlerde anlamı hatırlamayı bir kenara koyun, LSTM ve RNN’lerin training corpus’larında olan cümlelerinden daha uzun cümlelerle karşılaştıklarında sıkıntı yaşadıkları biliniyor.
Peki Transformer bunların hepsini nasıl başarıyor?
Buraya kadar geldiyseniz artık Transformer hakkında fikir sahibisiniz. İnternetteki birçok makale de size bunları anlatacak, bir de attention mekanizmasına kısaca değinecektir. Ama biz daha derine inelim. İlk olarak Transformer’ın şemasına bir göz atalım. Sonra tüm birimleri detaylı ve açık bir biçimde inceleyeceğiz.

Farz edin ki Türkçe’den İngilizce’ye çeviri yapıyoruz. Bu durumda belli bir odak aralığı belirleyip, örneğin 128 karakter, elimizdeki Türkçe metinden bu aralıktaki kelimeleri alacağız ve yukarıda gördüğünüz soldaki “input embedding” ve “positional embedding” ile her satırı bir kelimeye karşılık gelen bir matrise çevireceğiz.
Sonra bu matris “encoder” bloğuna girecek ve “multihead attention”, “residual connection”, “layer normalization” ile “multilayer perceptron” birimlerinden geçecek ve yeni bir matris elde edilecek.
Bu sırada “decoder” bloğuna bir adım önce yaptığımız çeviri, yani İngilizce kelimeler girecek. Bu kelimeler yine matrise çevirilecek ve benzer işlemlere tabi tutulacak. Ancak bu sefer ikinci “multihead attention” biriminde girdi olarak “encoder” bloğunun çıktısı alınacak. “Decoder” bloğunun çıktısı son bir lineer fonksiyondan geçecek ve buradan alınan çıktılar softmax fonksiyonundan geçerek sonraki İngilizce kelime için bize olası kelimeleri verecek. Metnin devamını çevirmek için sonraki 128 karaktere bakıp üstteki adımları tekrar edeceğiz.
Encoder — Decoder
Transformer’ı anlatmaya başlamanın en doğal noktası encoder decoder mimarisini anlatmak olur. Bu mimariyi anlamak gayet kolay, matematik formülleri yok: iki temel blok var: bir encoder ve bir decoder. Yukarıdaki şemada encoder solda, decoder ise sağda yer alıyor.
Encoder, “kodlayan”, veriyi, Türkçe cümleyi, girdi olarak alıyor ve içindeki fonksiyon ile bir koda çeviriyor. Bu koda NLP’de “context vector” yani bağlam vektörü deniliyor ve girdinin bütünü hakkında bilgi saklıyor. Decoder, “koddan geri çeviren”, ise girdi olarak encoder’ın çıktısını alıyor ve içindeki fonksiyonlarla bu kodu İngilizce’ye çeviriyor. Bu iki blokun içindeki fonksiyon ise herhangi bir nöral ağ, örneğin LSTM veya bizde olduğu gibi attention mekanizması olabilir.
Peki neden böyle bir “kodlama” zahmetine giriliyor? Bunun nedeni nöral ağların girdi ve çıktı verilerinin boyutlarının sabit ve önceden biliniyor olması gerekliliği. Tek bir nöral ağ değişken boyutta girdi alıp değişken boyutta çıktı veremez. Bu da bizi dil gibi değişken uzunluklu girdi ve çıktıların olduğu alanlarda kısıtlıyor. Sonuçta kimse tüm cümlelerini aynı uzunlukta kurmaz.
Bu mimaride ise encoder değişken boyutta girdiyi sabit boyutlu bir vektöre indirgemeyi öğreniyor, decoder ise bu veriyi okumayı ve istenen işi yapmayı öğreniyor. Bu sorunun padding gibi alternatif ama daha zayıf çözümleri de var.
Burada değinmeye değer bir nokta var. Bilgiyi bu örnekte bağlam vektöründe olduğu gibi sıkıştırabilmek, bazı YZ uzmanlarına göre genel YZ’ye giden yolda önemli bir adım. Hatta Wikipedia verisini belli bir boyutun altına sıkıştırmayı başarırsanız 500.000 Euro sahibi olabilirsiniz.
Bu durumu şöyle düşünebilirsiniz: Ben Türkçe metni okuyorum. Okuduklarımı sabit miktarda emojilerle özetliyorum ve size veriyorum. Siz de emojilere bakarak metni İngilizce’ye çeviriyorsunuz. Metinler uzadıkça ve karmaşıklaştıkça tüm metni emojilerle anlatmak da zorlaşacaktır tahmin ettiğiniz üzere. İşte bu sorunu çözmek üzere devreye attention giriyor.
Attention
Bir metni çevirirken belli kelimeler arasındaki ilişkilere dikkat ederiz. Örneğin:
Siz de Afyonkarahisarlaştıramadıklarımızdan mısınız?
Are you one of those people whom we unsuccessfully tried to make resemble the citizens of Afyonkarahisar?
Siz → you
De → one of those people
Afyonkarahisarlaştıramadıklarımızdan → whom we unsuccessfully tried to make resemble the citizens of Afyonkarahisar
Mısınız → are
Attention mekanizması da bu dikkatin nöral ağlarda karşılığıdır. Transformer’da kullanılan gelişmiş attention’a geçmeden önce RNN kullanan antika decoder encoder ağları için geliştirilmiş orijinal attention’ı emojili örneğimiz üzerinden özetleyelim.
Attention olmadan RNN Encoder Decoder:
Önüme gelen Türkçe metni kelime kelime okumaya başlıyorum. İlk kelimeyi 256 emojinin sığacağı bir kağıda yazıyorum. Sonraki adım için hem sonraki kelimeye bakıyorum hem de kağıda. Sonra aynı kağıdı alıp yeni bilgiler ışığında aynı kağıt üzerinde değişiklikler yapıyorum. Metnin sonuna böyle devam ediyorum, elimde üstünde bol bol değişiklik yaptığım gazi kağıdı size veriyorum. Siz de bu kağıdı alıp ilk kelime tahmininizi yapıyorsunuz. Sonraki adımlarda hem kağıdı hem de önceki tahmininizi düşünerek sonraki kelimeyi tahmin ediyorsunuz.
Buradaki sorun kağıdın “gazi” olması, yani küçük bir yere çok bilgi sıkıştırmak zorunda kalmam. Bu kağıda bakarak iyi bir çeviri yapmanız zor. İlk kelime hakkındaki emoji düşüncelerimden son kelimeye gelinceye kadar pek bir şey kalmamış oluyor çünkü büyük kısmı diğer kelimelere yer açmak için silinmiş.
Attention ile RNN Encoder Decoder:
İşlemin başı aynı, yine gazi kağıdı hazırlıyorum ancak her adımda kağıdın o anki versiyonunun fotokopisini çekiyorum. Ve bunların hepsini size veriyorum. Siz de çevirdiğiniz her kelime için size verdiğim kağıtların hepsini yeni icat ettiğiniz attention mekanizması ile puanlıyorsunuz ve kağıtları puanları kadar ağırlık vererek okuyorsunuz. Yüksek puanlı kağıtları dikkatli bir şekilde incelerken düşük puanlılara şöyle bir bakıp geçiyorsunuz. Böylece bir adım önce çevirdiğiniz kelimeye ek tek bir gazi kağıt yerine o anda çeviri yaptığınız kelimeyle en alakalı emojilere erişebiliyorsunuz.
Bu puanlamanın Fransızca İngilizce çeviriden gerçek bir örneği:

Şimdi medahı iftarımız Transformer attention’ına geçelim.
Attention is All You Need
Bu, Transformer’ın sunulduğu makalenin başlığı. Anlayacağınız üzere attention’ı her derde deva bir İsveç çakısı gibi kullanarak yukarıdaki klasik kullanımından öteye götürüyorlar. Bu “ötenin” ismi self attention, yani öz dikkat. Öz dikkatin amacı ise bir sekansın üyeleri arasında bağlantı kurmak. Yine bir örnek:
“Örnek bulmak zor oldu ama bu iyi bir örnek”
Biz bu cümleyi okuyunca “bu” ile kastedilenin “örnek” kelimesi olduğunu biliyoruz ancak klasik feed forward nöral ağların bunu öğrenmesi çok zor. RNN türevleri her ne kadar bir nebze bunun üstünden gelse de self attention mekanizması ile bu bağları nöral ağlardan bağımsız ve açık bir şekilde kurmak öğrenmeyi kolaylaştırıyor. Transformer’da önceki örnekte her adımda hesaplanan emoji kağıdının yerini tutan bu bağ klasik bir multilayer perceptron’a besleniyor ve öğrenme gerçekleşiyor. Ancak algoritmaların bu cümlede “örnek” ile kastedilenin cümlenin kendisi olduğunu anlamasına belki de onlarca yıl var :)
Attention’ın nasıl işlediğini tam olarak anlamak için işin matematiğine girmek gerekiyor. Korkmayın, yapılan matematik basit ve akla yatıyor.
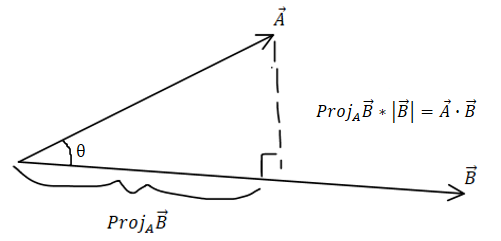
Önce biraz lineer cebir. Dot product, yani skalar çarpım, bize iki vektör arasındaki benzerliği bulmamızda yardım eder. Eğer iki vektörün dot product’ı yüksekse benzer, değilse benzer değillerdir. Dot product negatif de olabilir, bu durum vektörlerin farklı yönlere baktığını anlatır.

Harfleri Sayıya Çevirmek
Bizim benzerliklerini karşılaştıracağımız vektörler ise kelime vektörleri. Kelimeleri vektöre çevirmemizin nedeni bilgisayarların sayılarla daha hızlı çalışmaları ve daha önemlisi onlarla çeşitli işlemler yapabilmemiz. Bunu nasıl yapıyoruz sorarsanız şu kaynağa bakmanızı tavsiye ederim. Bu dönüştürmeye word “embedding” denir, yani kelimenin sayılara “gömülmesi”.
GloVe gibi modern embedding algoritmalarının arkasında yatan temel mantık şudur:
“Bana arkadaşını söyle sana kim olduğunu söyleyeyim.”
Kelimelerin vektörleri, yakınındaki kelimelere bakarak tanımlanır. Böylece vektörler bulundukları bağlama göre kelimelerin anlamsal özelliklerini özümserler. Bunun en klasik örneği “kraliçe” vektöründen “kadın”ı çıkarıp “erkek” ekleyince “kral” vektörüne ulaşmak. Bu adresten hangi kelimelerin yakın, yani dot product’larının yüksek olduğunu bulabilirsiniz.
Self attention’da da ilk olarak hangi kelimelerin benzediğini bulmaya çalışacağız. Bu benzerliğe “alignment” deniyor, alignment aslında hiza demek ve burada hizadan kasıt kelime vektörlerinin vektör uzayında gerçekten hizalı olmaları.

Scaled Dot Product Attention
Transformer “scaled dot product attention” kullanıyor. Yani alignment’ı dot product ile hesaplayacağız ve sonra ölçekleyeceğiz (scale). Örnek bir cümle:
Koşarken yemek yedik.
Burada “yemek” ve “yedik” kelimelerinin alakalı yani aligned olmalarını bekleriz. Çünkü bu iki kelime genelde bir arada kullanılır ve aynı bağlamda bulunurlar. Ancak “koşarken” ve “yedik” arasında böyle bir bağ olmadığı için o kadar benzer olmayacaktır. Ve tabi ki “yedik” kelimesi en çok kendine benzeyecektir. Benzerliği bulmak için ilk olarak dot product’larını alalım.
Gerçekte vektörleri GloVe gibi bir embedding’den initialize ederiz ve attention mekanizması zaman içinde bu vektörleri değiştirir. Kafanız karışmasın; aşağıdaki bu değişim değil, attention mekanizmasının kendisi.

Eğer bu skoru softmax fonksiyonundan geçirirsek benzerliği bulmuş oluruz. Burada softmax kullanmamızın nedeni benzerliklerin pozitif ve toplamlarının 1 olmasını istememiz, böylece sonraki adımdaki ağırlıklı ortalamayı alabileceğiz.

Sonra ise bu kelimeler için belirlenen ağırlıkları kelimelerin kendisiyle çarpıp ortaya çıkan vektörleri toplayacağız ve işimiz bitmiş olacak.

“Yemek” vektörünü “koşarken” kelimesi hiç etkilemezken “yedik” kelimesi biraz etkilemiş oldu.
Self attention dediğimiz şeyin mantığı bu. Klasik attention’ın farkı ise kıyasladığımız kelimelerin başka bir cümleye ait olması. Burada benim aklımı karıştıran şey şu olmuştu: sonuç olarak elde ettiğimiz vektörler başka kelimelerin vektörlerinin katsayıları ile çarpılıp toplanmışları olduğundan asıl vektör yok mu oluyordu? Tam aksine, yukarıdaki gibi kelimenin kendisi genelde diğerlerine baskın çıkıyor.
Ancak bu işlemi her kelime için, cümledeki diğer tüm kelimelerle yapmak istiyoruz. Bu halde işlemi matrisler ile ifade edebiliriz. Ve tabii ki teorinin uygulanması daha nüanslı olacak. Her adımda kelimeler için aynı vektörü kullanmaktansa attention işlemindeki 3 rol için 3 ayrı matris kullanacağız. Yukarıdaki örnek için bu roller:
- Query: Seçip diğer kelimeler ile karşılaştırdığımız kelime— yedik
- Key: Karşılaştırdığımız kelimeler (tüm cümle) — koşarken yemek yedik
- Value: Hesapladığımız ağırlık ile çarptığımız kelimeler (tüm cümle) — koşarken yemek yedik
Bu durumda işlemimizi elegant bir formülle ifade edebiliriz.

Örneğimizi bir de bu formda inceleyelim. Önce Query ve Key’i çarpıp her kelimenin diğer kelime ile olan alignment’ını hesaplayalım.

Şimdi bu alignment’ı başlangıçtaki vektörlerimizin boyutunun kareköküne bölüp softmax’larını alalım.

Bu bölme işlemi nereden çıktı diyeceksiniz. Attention mekanizmasının ismindeki “scaled” kısmı işte bu bölme işleminden geliyor. Burada niye böyle bir ölçekleme yapıyoruz peki? Bu sorunun cevabı direk training ile alakalı. (Bölüm 2'de training’i daha detaylı işleyeceğiz.)
Nöral ağlarda trainingi hatırlayın: error function’ın modelimizdeki parametrelere göre nasıl değiştiğini bulup parametrelerimizle oynuyorduk. Bu değişimi bulmak için modelimizin birimlerinin (mesela bir nöral ağ katmanının) türevlerini alıyorduk. Attention mekanizması da bu layerlardan farklı değil, hatta Tensorflow veya Torch ile yazılmış Transformer modellerinde bir nöral ağ gibi dense linear layer olarak kullanıldıklarını görebilirsiniz.
Eğer (4)’ü bu bağlamda incelerseniz softmax’in türevini almamız gerektiğini görecekseniz. Yüksek değerlerde ise softmax’in türevi 0’a yaklaşıyor, bu da gradient’ı düşürüyor ve neticesinde öğrenmeyi zorlaştırıyor. İşte bu yüzden softmax fonksiyonunun içi normalize ediliyor ki bu yüksek değerlere ulaşmayalım.
Bu normalleştirme faktörünün özellikle kelime vektörünün boyutunun karekökünün seçilmesinin sebebi ise şu: iki boyutlu Reel uzayı düşünün. R². Burada (c,c) koordinatlarına sahip olan bir vektörün uzunluğu karekök(2*c) olacaktır (Eşkenar dik üçgenin hipotenüsü gibi düşünebilirsiniz). R³’te ise karekök(3*c). Yani matrisin boyutu arttıkça vektörlerin uzunluğu karekök(boyut) oranı ile artıyor, matrislerin boyutları ile orantılı bir şekilde normalize edilmesinin sebebi bu.

Son olarak (6)’da elde ettiğimiz ağırlık matrisini Value matrisi ile çarpıyoruz ve sonuca ulaşıyoruz. Fark ettiyseniz attention dediğimiz şey aslında ağırlıklı ortalamadan ibaret. Mesele bu ağırlıkları öğrenmek.

Peki bu öğrenmeyi gerçekleştirmek için training’de Q, K, V mi train ediliyor, diye soracaksınız. Cevap hayır, train ettiğimiz ayrı weight matrisleri var. Q, K V’ye bu weight matrisleri, cümlenin word embedding matrisleri ile çarparak ulaşıyoruz. Ayrı matrisleri train etmemizin sebebi train edilen matrisin boyutu üzerinde kontrol sahibi olmak.

İşte scaled dot product attention, aynı Transformer’da olduğu gibi! Yoksa öyle mi? Aslına bakarsanız, Transformer’ın dayandığı bir atasözü daha var:
“Bir elin nesi var iki elin sesi var.”
Aynı iki kelime arasında farklı ilişkiler olabilir, örneğin “yemek” ve “yedik” hem bağlam olarak hem de nesne — fiil ilişkisi bakımından bağlı. Yalnız bir attention kafası bu ilişkileri öğrense de bu bilgileri tek bir vektöre sıkıştırmak zorunda kalıyor. Bu size bir şeyi anımsattı mı? Attention’ın çözmek için yola çıktığı bilgiyi sıkıştırma sorunu kendisini de etkiliyor.

Multiheaded attention, yukarıda anlattığım mekanizmaları paralel olarak çalıştırıp sonuçlarını birleştiriyor. Bu kafaların mimarileri tamamen aynı, yalnızca weight matrisleri farklı, böylece farklı ilişkiler öğrenebiliyorlar. Örneğin kafalardan birisi dil bilgisi ilişkilerini öğrenirken, bir diğeri anlamsal ilişkileri öğrenebiliyor. Buradaki tek sorun farklı kafalardan gelen sonuç matrislerini birleştirmek, bunların hepsini toplasak normal attention’dan ne farkı kalır ki? Bunun çözümü kafalardan gelen tüm matrisleri concatenate edip (uçuca birleştirip), öğreneceğimiz yeni bir matrisle çarpmak.

Böylece multihead attention sonlanıyor ve Y matrisi MLP (multilayer perceptron)’ye girmek üzere yoluna devam ediyor…
Sonuç
Transformer’ın kalbi attention’ı işledik ve ilk bölümün sonuna gelmiş olduk. İkinci bölümde byte pair encoding, MLP, positional encoding, layer normalization, residual connection ve logit kavramlarını inceleyip tüm bunların attention ve decoder-encoder ile bir araya gelerek Transformer’ı nasıl yarattığını, yani büyük resmi göreceğiz. 23 Ekim’de, ikinci bölümde görüşmek üzere!
Öğrendiklerimiz:
Transformer modelinin hikayesi
Encoder decoder mimarisi
Multiheaded scaled dot product attention
Edit — 25 Ekim: ODTÜ Yapay Zeka Topluluğunun kurulması ile biraz yoğun bir dönem yaşıyorum, ikinci bölüm biraz gecikecek. Anlayışınız için teşekkür ederim.
Kaynakça
- https://arxiv.org/pdf/1409.0473.pdf — attention
- https://arxiv.org/pdf/1706.03762.pdf — transformer
- https://arxiv.org/pdf/1409.3215.pdf — encoder decoder
- http://peterbloem.nl/blog/transformers
- http://jalammar.github.io/illustrated-transformer/
- https://www.topbots.com/dissecting-the-transformer/
- https://machinelearningmastery.com/transduction-in-machine-learning/
- https://www.researchgate.net/profile/Shen_Leixian/publication/325856086/figure/fig1/AS:723221292789765@1549440801787/Softmax-function-image.png — softmax foto
- https://pics.me.me/when-your-music-helps-other-people-from-ironic-he-could-25735619.png — ironic foto
- https://miro.medium.com/max/1236/1*_cWv-in-l9VBx0BQf-PsCA.jpeg — attention matrix
- https://miro.medium.com/max/1002/1*WP8NOo8DHVUrseg222PDPQ.png — dot product foto
- https://corpling.hypotheses.org/files/2018/04/3dplot-500x381.jpg — vector space foto

{kind=link}
{kind=link}